

"3分で読める"シリーズの第3弾、AIに関するコラムです。
是非ご覧ください。
≪ 本コラムの記事一覧はこちら
第2回:AIの種類と機能 ー「識別」から「生成」へのパラダイムシフト
AI技術の進化は、データの処理方法によって大きく2つの時代に区分できます。
それが「識別系AI」と、近年爆発的な普及を見せる「生成系AI」です。
識別系AI(Discriminative AI):正解を導く分析装置
2010年代のAIブームを牽引したのは識別系AIでした。
これは、入力されたデータが「何であるか」を判断・分類・予測することに特化しています。
- 機能
画像認識(これは猫か犬か)、音声認識(何と言ったか)、
異常検知(この部品は正常か)、需要予測(明日の売上はいくらか)などがあります。
- メカニズム
入力データを解析し、あらかじめ学習した境界線に基づいてデータを分類します。
出力される情報量は、入力に対して非常に小さい(ラベルや数値のみ)のが特徴です。
- ビジネス応用
工場のラインでの不良品検知、銀行における不正送金のフィルタリング、
スマートフォンの顔認証ロック解除など、効率化と自動化の基盤となっています。
生成系AI(Generative AI):確率による創造装置
2020年代に入り登場した生成AIは、従来のAIとは根本的に異なる挙動を示します。
これは、学習データの特徴を捉え、そのパターンに基づいて「新しいデータ」をゼロから創り出すAIです。
■ 確率分布とサンプリングの数理
生成AIが「創造」を行える理由は、
大量のデータ(画像やテキスト)を読み込み、そのデータの「確率分布(Probability Distribution)」を学習している点にあります。
- 確率分布の学習
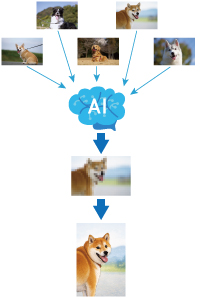
例えば、大量の犬の画像を学習することで、AIは「犬らしいピクセルの並び方」の確率分布を構築します。
これは高次元空間におけるデータの地図のようなものです。 - サンプリング(生成)
新しい画像を生成する際、AIはこの確率分布に従ってランダムにデータを抽出(サンプリング)します。
分布の「濃い」部分(犬らしく見える領域)からデータを抽出することで、学習データには存在しないが、いかにも犬らしい画像を生成することが可能になります。
この「確率的」なプロセスこそが生成AIの最大の特徴です。
識別系AIが、常に一つの正解(分類結果)を求めるのに対し、
生成系AIは、サイコロを振るように、同じ入力に対しても毎回異なる出力を生成できます。
これが「創造性」の源泉であり、同時に後述(第三回)する「ハルシネーション(嘘)」の原因にもなります。
| 識別系AI | 生成系AI | |
| 主なタスク | 分類、回帰、予測 | コンテンツ生成、変換 |
| 出力の情報量 | 小さい(ラベルや数値) | 大きい(文章、画像、動画) |
| 学習対象 | データとラベルの境界線 | データの分布そのもの |
| 得意分野 | ルーティンワークの自動化、分析 | クリエイティブ支援 アイディア出し |
お読みいただきありがとうございました。
次回のコラムは1月29日(木)更新予定です。